
On Euler, infinite series, the question of where AI progress is actually heading, and why the proof we want may be blocked by a theorem from 1953. Sister piece to Gödel on the Couch – Are Ethical Frameworks fundamentally flawed and might that be a good thing?. Gödel showed indirectly that ethical frameworks for AI cannot be complete. This essay argues that safety proofs for self-modifying AI cannot be general. Two limitative theorems, one alignment problem.
I. What Euler knew about the long run
Leonhard Euler spent a serious portion of his working life on a deceptively simple question: when you add infinitely many numbers, does the sum settle on a finite value or run away to infinity?
It sounds like the kind of thing a mathematician with too much time on their hands might worry about. It is not. The convergence question is one of the deepest in mathematics, and Euler’s contributions to it shaped how we still think about limits, infinity, and the long-run behaviour of additive processes.
The lesson he drove home, again and again, is that you cannot tell from the early terms.
Look at these two series:
1 + \tfrac{1}{2} + \tfrac{1}{3} + \tfrac{1}{4} + \tfrac{1}{5} + \cdots 1 + \tfrac{1}{4} + \tfrac{1}{9} + \tfrac{1}{16} + \tfrac{1}{25} + \cdotsThe first is the harmonic series. It diverges — it grows without bound. The second is the series Euler famously summed in solving the Basel problem : it converges, to \pi^2/6.
Compare the first dozen terms of each. They are nearly indistinguishable. The harmonic series and the Basel series part company only deep into the limit, far past where any finite inspection can reveal which way they go. To know which series you are looking at, you need a proof — not a vibe, not a pattern, not extrapolation from the first few entries.
This matters for AI because every camp in the current debate agrees on one thing : we are in the early innings of the AI revolution. The doomers say it. The accelerationists say it. The skeptics insisting it will plateau say it. What they all mean by “early innings” is the same thing: we have only seen the first few terms. And that is exactly the situation in which Euler tells us our convictions about the limit should be at their lowest.
If the first dozen terms of \sum 1/n and \sum 1/n^2 are visually indistinguishable, then the first dozen years of AI scaling cannot, by the same logic, tell us whether we are heading for a bounded plateau, an unbounded but slow climb, or a phase transition into something faster. Anyone who claims otherwise — in either direction — is doing what pre-Eulerian mathematicians did with series: pattern-matching on early entries and calling it inference. The early-innings framing is a confession of low information, even when its speakers use it as if it conferred high confidence.
This is the question I want to ask, then, holding our convictions appropriately low: which series are we probably in?

II. The catalog
Several famous series, each with a clear mathematical signature, suggest themselves as candidate models for technological progress.
Geometric series, \sum a^n. Converges if |a|<1, diverges if |a|\geq 1. The model for compounding processes. Moore’s law, in its classical form, is geometric on the resource side: a doubling every 18 to 24 months means each term is twice the last.
Harmonic series, \sum 1/n. Diverges, but unbearably slowly — like the natural logarithm. Sum a million terms and you reach about 14. There is no ceiling, but each new unit costs exponentially more than the last.
Basel series, \sum 1/n^2. Euler’s beautiful result: the sum is finite, \pi^2/6. The model for technologies that genuinely saturate. Aircraft cruise speed has barely moved since the 1960s. Single-core CPU clock speeds plateaued around 2005. Each generation contributes less than the last, and the total is bounded.
Grandi’s series, 1-1+1-1+\cdots The Eulerian troublemaker. Diverges in the strict sense, but Cesàro-summable to \tfrac{1}{2} — averaged across many terms it behaves as if it had a stable value. A surprisingly good model for hype cycles. AI winters and AI summers, averaged across decades, give us something halfway real.
Each of these is a plausible analogue for some aspect of technological progress. The question is which one fits AI.
III. Where AI probably sits
We don’t know yet, and the question is partly empirical and partly definitional. But the best current evidence puts us in the harmonic series — or, more precisely, in something harmonic-shaped.
The empirical scaling laws of large language models — the Kaplan and Hoffmann results and their successors — are power laws with small exponents.
Loss drops with compute, but each doubling of compute buys a fixed additive improvement, not a fixed multiplicative one. A keen observer will note that this is not, strictly, \sum 1/n; it is L \propto C^{-\alpha}, a different beast in the limit. Fair. But qualitatively the two stories agree on the thing that matters: slow climb, no ceiling, exponentially expensive in cost-per-fixed-improvement.
This thesis is the one I’ll call slow divergence. There is no hard ceiling, but each increment costs exponentially more in resources. Progress continues as long as someone is willing to pay, and the upper bound is set by economics rather than physics.
Two competing theses bracket this one.
Saturation is the Basel-style claim: capability is a \sum 1/n^2 series, and we are approaching its finite sum. Transformers and scaling extracted most of the available signal from the corpus of human text. The next architecture will do the same and bound out somewhere recognisable. Aviation finished its speed era in 1965; AI may be finishing its capability era now, give or take a decade.
Geometric divergence is the foom-shaped claim: at some threshold, AI contributes to its own research and development enough that the terms themselves grow. The sum is no longer \sum 1/n but \sum r^n with r>1. This is the recursive self-improvement scenario.
Slow divergence is the empirical best fit. Saturation is the optimistic fallback. Geometric divergence is the open phase-transition question — whether at some recursion threshold, the series-type itself changes.
IV. The observer problem
There is a complication the math doesn’t capture: the observer is not a neutral instrument.
Human cognition appears to compress capability shocks logarithmically. Each major step in AI capability feels less impactful than the last, even when the underlying improvement is larger in absolute terms. Talking to a system that is plausibly smarter than oneself feels less revolutionary than talking to GPT-3.5 felt three years ago — not because less is happening, but because the brain has updated its prior on what is possible.
This dampening is partly adaptive. It is the cognitive analogue of the Weber-Fechner law for sensory perception: equal ratios feel like equal increments, which is why we measure sound in decibels. A nervous system that responded with full surprise to every capability jump would not be functional. The compression keeps individual humans operational in a world where the curve is steepening.
But it produces a tension. The same mechanism that prevents cognitive overload also prevents collective recognition of which series we are actually in. Constant velocity feels like stillness. Accelerating velocity feels like the new normal. If the underlying process is geometric and the perceptual transform is logarithmic, the result is a perceived experience of linear progress on top of an actual exponential trajectory. The dampening protects the nervous system and obstructs the epistemics in the same motion.
Which means: the felt sense of “this isn’t that different from last year” cannot be used as evidence about long-run trajectory. The math has to do that work, because the perception is structurally unreliable.
V. When Physics can provide x-risk buffer
A second complication cuts the other direction, and it is the reason this piece does not lean to either side of the doom fence.
Eric Drexler coined the phrase “grey goo” in 1986 to describe self-replicating nanomachines disassembling the biosphere for raw materials. The scenario was absorbed into the AI doom literature as a canonical kill-mechanism: a misaligned superintelligence invents nanotech, releases self-replicators, biosphere converts in minutes. Drexler himself walked the scenario back significantly two decades later. Self-replicators in the open environment are harder to build than the controlled industrial versions and serve no economic purpose. The threat survives in the discourse because it is vivid, not because nanotech researchers consider it likely.
A nanobot swarm operating in millisecond synchrony across a continent runs into the speed of light long before it runs into engineering challenges. Coordinating large distributed swarms requires electromagnetic communication, which has hard floors: latency, bandwidth, signal-to-noise, jamming susceptibility, attenuation. Local clusters can coordinate fast. Global swarms cannot. Faraday cages are real. Jamming is real.
This defeats the fastest versions of doom. The biosphere-in-minutes scenario requires something close to magic — physics violations dressed in technical language. Strip the magic and the timeline stretches from minutes to weeks or months, which puts the scenario inside the window where institutions can in principle respond.
So far so encouraging. The argument has a known overreach, though.
A common move from this point is the chess analogy: a beginner cannot predict how Stockfish will beat them only does it beat them. This is often used as a get out of counterargument-jail free card by doomers. They know Stockfish cannot move through check, but when confronted they quickly retreat to: when caught by having our cake and eating it too,we simply move to another baker . Even an arbitrarily strong player is bound by the rules of the game. The same, the argument goes, applies to ASI: bound by physics, no supernatural moves.
The analogy is sharper than it should be. Chess is a closed formal system humans designed; the rules are fixed and complete. Physics is a model of an open system, and our model is known-incomplete. The relevant historical reference class is not “things that violate physics” but “things consistent with physics that humans had not yet discovered.” Nuclear weapons were in that set in 1900. Radio was in that set in 1800. The set is non-empty and has historically contained civilization-altering capabilities.
The chess argument also subtly defeats itself. The beginner still loses every game. Knowing the grandmaster is bound by the rules does not help the beginner construct a defense — it merely confirms that the loss will be legal. Physics being a constraint does not tell you the constraint is tight enough to save you.
What survives, then, is a real but bounded resilience claim. Many specific doom scenarios in the literature smuggle in physics violations or near-violations, and when you tighten the physics, the timelines stretch into windows where human response becomes possible. Bostrom’s vulnerable-world hypothesis weakens against grey-goo-class threats. It does not weaken against threats that do not depend on speed: gradual loss of control over critical infrastructure, engineered pandemics with long incubation, economic and epistemic capture by AI-augmented actors. None of these break physics. None of them are defeated by the latency argument.
The actual risk surface, then, has a specific shape: not “things that exploit physics” but “things that exploit institutional response time.” Physics is a non-trivial ally against the first class. It is silent on the second.
VI. The recursion threshold
This brings us back to the series question.
The boundary between slow divergence and geometric divergence — between \sum 1/n and \sum r^n with r>1 — is precisely the recursion threshold. It is the point at which a system contributes meaningfully to the design of its successor. Below that threshold, progress is bounded by what humans can build with AI as a tool. Above it, the terms of the series themselves grow, because each generation produces the next.
The shift is qualitative, not just quantitative. A non-recursive process can be described by a series — a fixed function of n. A recursive process is a different mathematical object: a recurrence relation, x_{n+1} = f(x_n), where each term depends on the last. Recurrence relations can do things that simple series cannot. They can transition from stable to chaotic via well-understood routes. They can lock in sensitivity to initial conditions. They can become deterministic-but-unpredictable in the technical sense.
The question of whether ASI is safe, then, separates into two questions, and they have different shapes.
For non-recursive systems — AI used as a powerful tool, not a self-modifying agent — the safety question is engineering. We can build verification, monitoring, oversight. The system’s behavior is a function of its inputs, and we can constrain the inputs and audit the outputs. Hard, but tractable.
For recursive systems, the safety question becomes something else. And here we hit Rice.
VII. The proof in the pudding
The proverb the proof of the pudding is in the eating is a folk-epistemology claim: the true value of something can only be judged by experience. You can theorise a recipe all you like; the only honest test is whether the dish is good when eaten.
This proverb has been promoted, in the alignment debate, into a strategy. The most popular optimist position is some version of it: we don’t need a proof of ASI safety in advance. Even if humans cannot align ASI, we will use ASI to align ASI. The proof is in the pudding. Variants of this argument show up in serious technical writing and in casual hand-waving, and they share a common shape — they replace a question of provability with a question of trust in eventual experience. It is even hidden in the bold statement of a Nobel laureate that often quotes one of his childhood mantras: first solve intelligence, then everything else.
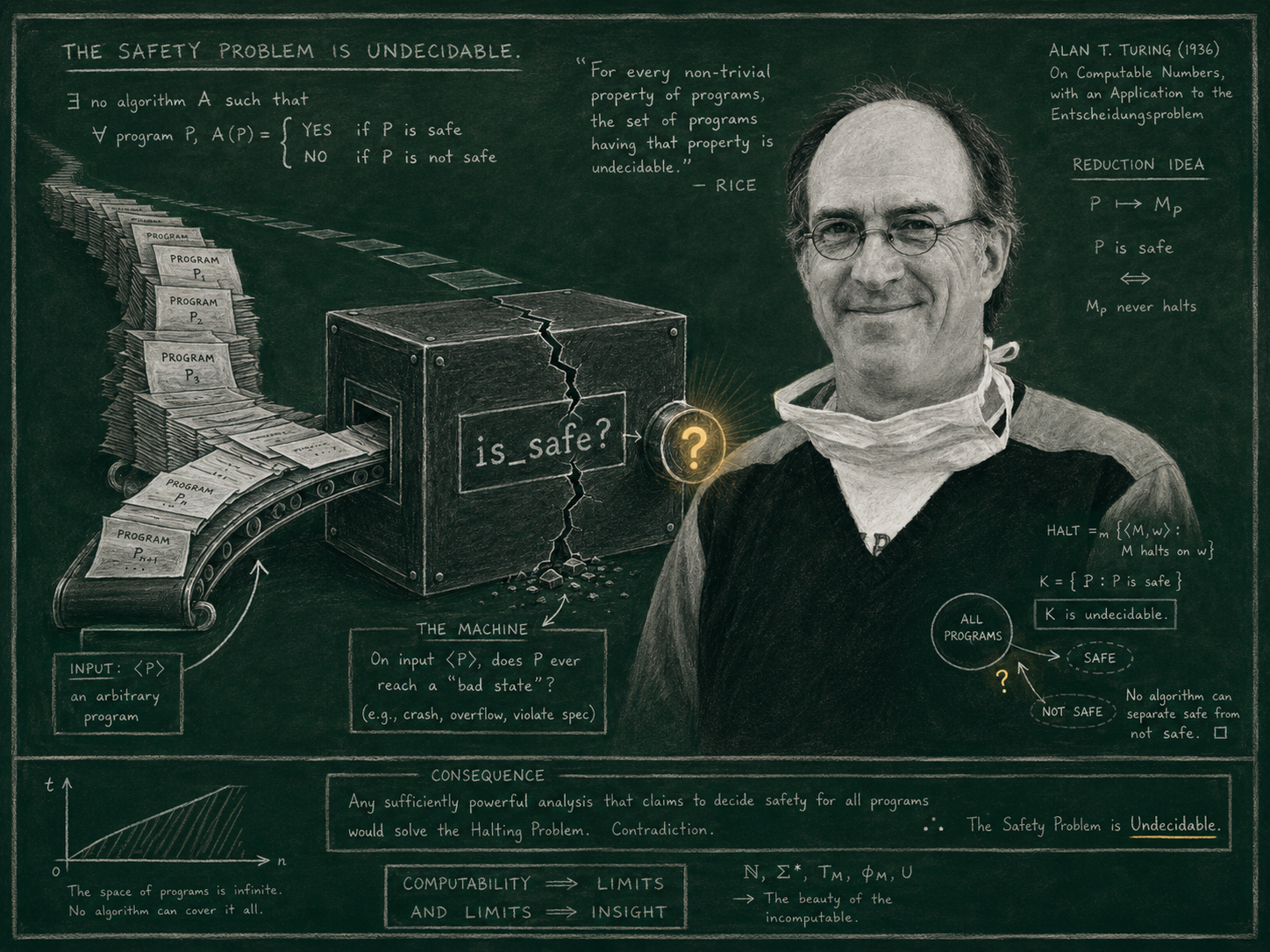
Henry Gordon Rice proved a theorem in 1953 that says, very precisely, that this is not a strategy. It is a pipedream.
Rice’s theorem says: any non-trivial semantic property of arbitrary programs is undecidable. There is no general algorithm that takes an arbitrary program as input and reliably tells you whether it has a given non-trivial behavioural property. “Halts on all inputs” is undecidable. “Computes a specified function” is undecidable. “Is safe” is undecidable, for any reasonable definition of safe.
This is not a contingent engineering limit. It is a theorem at the level of solidity of Gödel’s incompleteness results. Rice cannot be engineered around. Rice is what the universe of computation looks like.
What this means for the question of ASI safety is uncomfortable.
If we want a proof of ASI safety in the strong, universal sense — a theorem that takes an arbitrary self-modifying AI system and outputs SAFE — Rice tells us no such theorem exists. Self-modifying systems generate arbitrary programs as their successors, and predicting safety properties of arbitrary programs is precisely what Rice rules out.
There is a predictable accelerationist counter at this point, and it deserves a clean response. The counter runs: Rice’s theorem applies to limited intellects like us, but a sufficiently advanced ASI could defeat it. Use ASI to verify ASI. Rice for humans is like check for Stockfish — a hard rule we cannot move through, but a stronger player might.
This argument fails, and it fails for a precise reason. Rice is not a constraint on intellect. It is a constraint on computation. It applies equally to humans, to Stockfish, to current LLMs, to any conceivable ASI, and to any oracle short of a literal halting-problem solver — which itself is provably impossible. Rice says: no Turing machine, however large, however clever, can decide the safety of arbitrary Turing machines. The intellect of the verifier is not the variable. The class of programs being verified is the variable. Make the verifier as smart as you like; if it remains a computational system, the theorem still binds it.
The Stockfish-and-check analogy actually inverts here. Check is a rule of chess , internal to a closed formal system. Rice is a rule of computation itself , the system inside which Stockfish — and any ASI — necessarily operates. Stockfish cannot move through check because chess forbids it. An ASI cannot decide arbitrary program safety because mathematics forbids it. Asking ASI to defeat Rice is structurally the same as asking Stockfish to win a game by moving through check. The constraint is constitutive, not adversarial.
A more honest version of the counter would say: an ASI might solve safety for the specific class of successor systems it cares about, even if it cannot solve safety in the general case. That is true and unalarming, because it is what humans already do with formal verification — bounded proofs about specific architectures under specific assumptions. It does not give you universal safety. It gives you the same partial guarantees we already have, possibly faster. The proof we wanted does not arrive merely because the prover got smarter.
Yoshua Bengio’s recent work on what he calls Scientist AI , developed under his nonprofit LawZero is sometimes read as a candidate for this kind of proof. It is not. Bengio is explicit that his proposal is architectural, not theoretic. The bet is that non-agentic, world-model-only systems — systems that produce probabilistic predictions rather than goal-pursuing actions — sidestep the dangerous regime by avoiding agency in the first place. The safety case rests on removing the failure mode, not on proving its absence.
This is the right move available, and it is also the most that is available. This pudding cannot be proven in a Rice-limited computation world. It can only be portion-controlled, and humanity will be its own taster.
What is left, then, when universal proof is off the table:
– Proofs about specific architectures under specific assumptions, scaling poorly to systems of LLM complexity.
– Probabilistic guarantees that bound expected behaviour without bounding worst case.
– Bounded-rationality results that hold if a system’s optimization power is capped — circular for the ASI question, since the cap is the thing in dispute.
– Architectural bets like Scientist AI, which avoid the problem rather than solving it.
And one policy implication follows from the math itself: if we ever allow true self-recursion, we enter a regime that is provably unanalyzable, not merely hard to analyze. Bounded recursion by policy is not paranoia. It is what Rice’s theorem leaves us when we want to keep the trajectory predictable.
This is a strong argument for using AI for everything except self-improvement. The argument is not that recursion is risky — though it is — but that recursion is the boundary at which the math itself stops being on our side.
VIII. Euler and Rice
Two mathematicians, two centuries apart, frame the situation.
Euler showed that the limit question, in pure mathematics, is decidable. With enough work, you can prove which series converge and which diverge. The first dozen terms don’t tell you, but the proof eventually does.
Rice showed that the same question, in code, is not decidable. There is no general procedure to settle the safety of an arbitrary program. The proof you want does not exist, by theorem.
AI sits between the two. Its trajectory is currently best modeled as a slowly divergent series, harmonic in shape, costly to advance but unbounded in principle. The question of whether it stays in that regime or transitions to geometric divergence depends on whether we cross the recursion threshold that is sometimes called Singularity. Below that threshold, Euler-style analysis applies: hard, but possible. Above it, Rice-style undecidability bites.
The proof we want — a clean theorem that says the pudding is safe to eat — is not in the pudding. The math we have says it cannot be there. What remains is to keep the recursion bounded, the architectures non-agentic where possible, the institutional response time short, and the perceptual dampening corrected against the actual numbers rather than the felt sense.
