
An Inconvenient Coincidence
In chapter 22 of my novel The Goldberg Version, a detective named Van-Turing chases a number. The number is 32. He doesn’t know why it is 32; he only knows that everyone who has ever come close to the case has, at some point, written or spoken the number Thirty-Two, and subsequently come to a conclusion that was either very useful or very fatal.
In the scene, Van-Turing loses his temper and shouts, in English, “Damn!” His counterpoint, the Philosopher Bertrand Russell, looks counts on her fingers, and says, calmly, “Thirty-two.”
D + A + M + N = 4 + 1 + 13 + 14 = 32.
The German translator of the novel faced a problem. “Verdammt!” does not sum to 32. Neither does “Mist!”, “Scheiße!”, or any of the other colorful options available in the language of Goethe. After several sleepless nights he replaced the outburst with “Olé!” — 15 + 12 + 5 = 32 — and justified the decision in a footnote roughly four times longer than the scene itself.
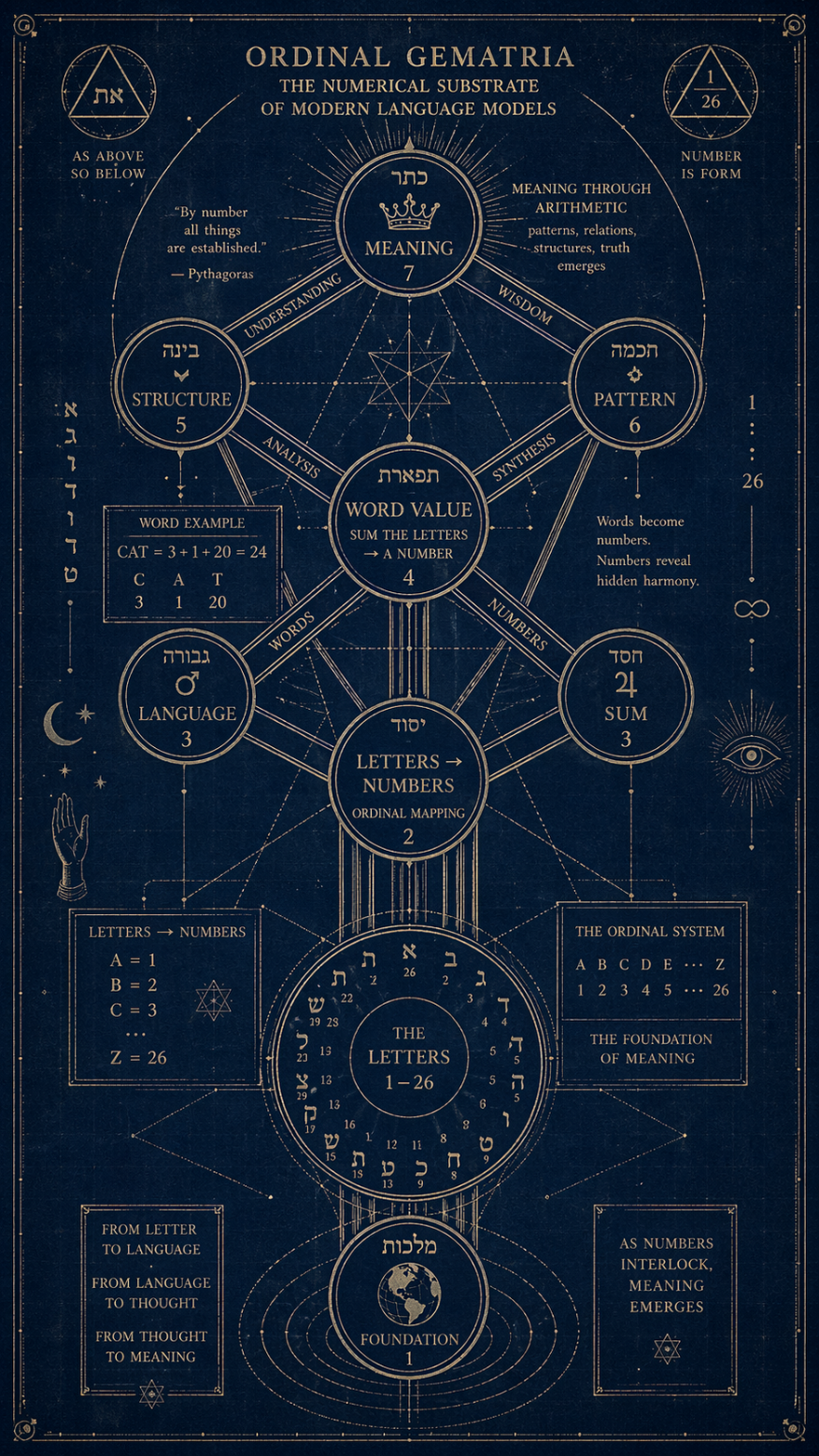
Russell, in the novel, gives the method a name: Ordinal Gematria. The Gematria part is old. The ordinal part gives it an aura of mathematical authority we are in urgent need of, otherwise anybody could call us silly.
The Math Mystics
Assign each letter of the alphabet its position: A=1, B=2, … Z=26. Sum the letters of a word. Treat the resulting number as meaningful. That is the entire method. It fits on the back of a beer mat, which is roughly where it belongs.
And yet it is a family tradition going back about three thousand years.
Hebrew Gematria. Each Hebrew letter has a fixed numerical value (aleph=1, bet=2, gimel=3, and so on, with the later letters jumping to tens and hundreds). Words sharing a sum are held to be mystically linked. The canonical example: yayin (wine) = 70 = sod (secret). Hence the Talmudic proverb: when wine enters, secrets come out. The rabbis did not need neuroscience to notice this. They had dinner parties.
Greek Isopsephy. The Hellenic cousin. Alpha=1, beta=2, etc. The number of the beast — 666, Revelation 13:18 — is almost certainly isopsephy for Neron Kaisar in Hebrew transliteration. An apocalyptic riddle encoded as arithmetic homework for people who could read two alphabets. John of Patmos, in this reading, was the first writer to slip a steganographic payload past a censor, and we are still arguing about whether he knew what he was doing.
The Pythagoreans went further than all of them. For Pythagoras and his pupils, numbers were not descriptions of reality. They were reality. A word’s numerical value was not a metaphor for its meaning — it was its meaning. Everything else, including the word itself, was a lossy encoding.
This sounds insane until you remember what the rest of the 21st century Hyperscalers is spending its GPU budget on. Basically Gematria on an astronomical scale.
A Musical with numbers needing no singers but calculators
Before we get to the GPUs, there is one composer we have to stop for.
B + A + C + H = 2 + 1 + 3 + 8 = 14.
Fourteen is everywhere in the surviving manuscripts of Johann Sebastian Bach. He joined the Correspondirende Societät der Musicalischen Wissenschaften as the 14th member, and waited for a spot to open up so he could be member 14 specifically. The Art of Fugue has 14 contrapuncti in the final layout. The chorale “Vor deinen Thron tret ich hiermit”, dictated from his deathbed, has 14 notes in the opening phrase — and 41 (the reversal) in its total thematic content. If you take J. S. B. A. C. H. as the full initials and sum it in the same scheme, you get 41. Bach appears to have enjoyed this.
He also used his name as a melody. In German musical notation, B means B-flat, and H means B-natural — a quirk of medieval solmization that exists in no other major European language. This means the four letters B-A-C-H can be played on a keyboard as four actual notes: B♭, A, C, B♮. The resulting motif is chromatic, haunting, and structurally unstable — exactly the kind of thing a composer uses when he wants to sign his name without writing it. Bach slipped the motif into the final, unfinished Contrapunctus XIV of the Art of Fugue, at the moment the manuscript breaks off. He was, the evidence suggests, writing his own name into the fabric of the piece at the exact point he stopped being able to write.
Consider what is happening here. The same four letters sum to a number (gematria), and name four pitches (notation), and spell a human being (orthography). Three parallel encodings riding on one string of symbols. A medieval Kabbalist would have recognized the structure immediately. A modern ML engineer would call it a multimodal embedding: the same token mapped simultaneously into several representational spaces. Bach, in Leipzig, in the 1740s, was doing multimodal embeddings by hand, with a quill, for a music-theoretic joke no one was quite supposed to notice.
This is the clue we need. The arithmetic hiding under language is not confined to language. It shows up wherever symbols carry meaning: in alphabets, in staves, in DNA triplets, in the token IDs inside a transformer. The Pythagorean intuition was not that numbers live inside words. It was that numbers live inside meaning, and words are just one place they happen to surface.

Multidimensional Mappings
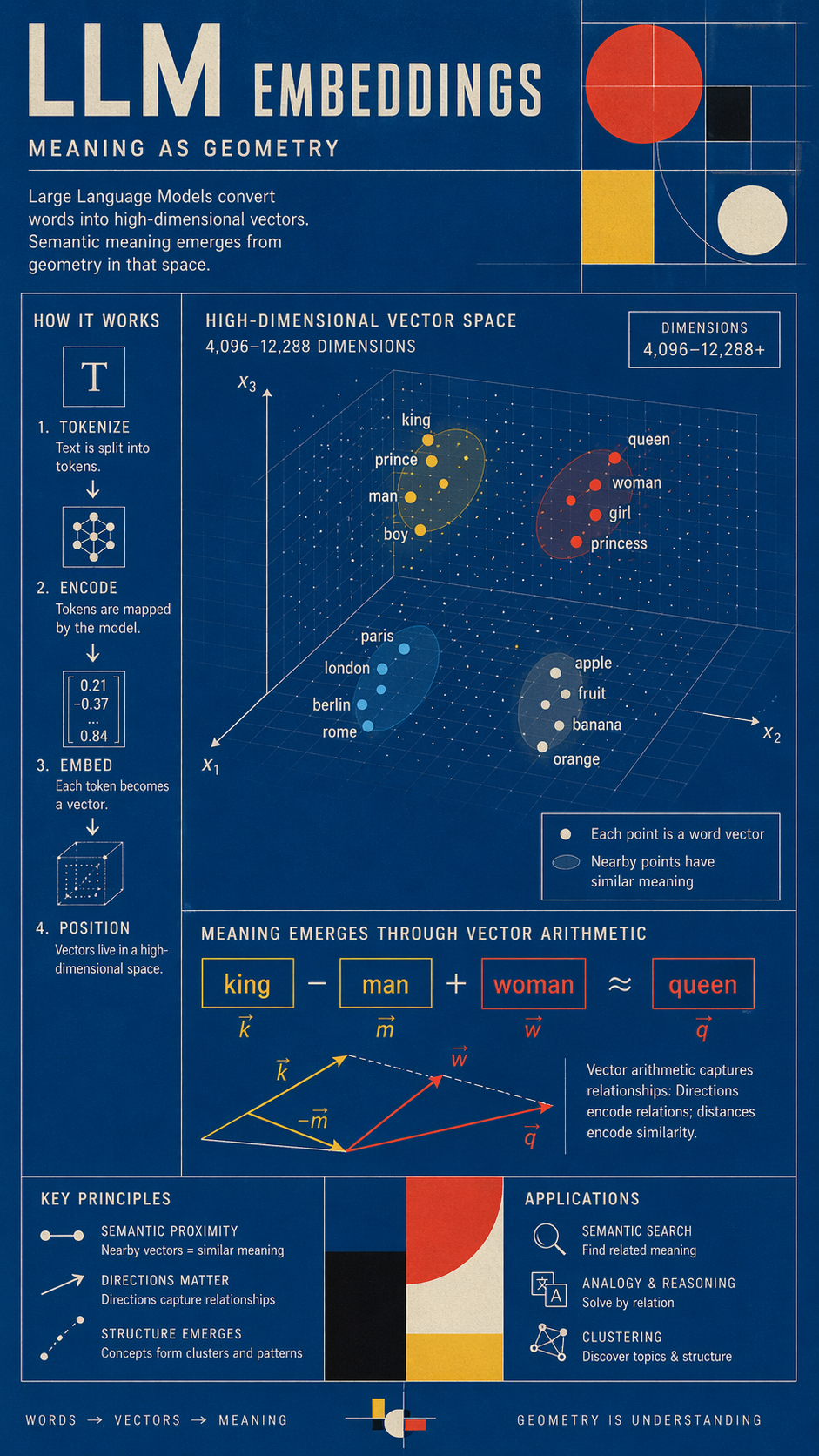
A modern large language model does not read text. It cannot read text. It is, at the lowest level, a machine that does arithmetic on vectors. When you type a word into GPT-4 or Claude or any of their cousins, the first thing the machine does is convert the word into a list of numbers — typically between 4,096 and 12,288 of them. That list is called an embedding. It is the word’s numerical position in a space of thousands of dimensions.
Meaning, in an LLM, is not stored in the word. It is stored in the location of the word. Words that are semantically close — “king” and “queen,” “wine” and “secret,” “Damn” and “Olé” — occupy nearby regions of this numerical landscape. The model derives meaning by performing arithmetic on these vectors. The most famous demonstration, first shown by the word2vec paper in 2013:
vector(“king”) − vector(“man”) + vector(“woman”) ≈ vector(“queen”)
Semantic relationships encoded as geometric operations. Subtract maleness, add femaleness, arrive at the female cognate. No human told the model that “king” was masculine. It figured out the axis by looking at several billion sentences and noticing where the points clustered.
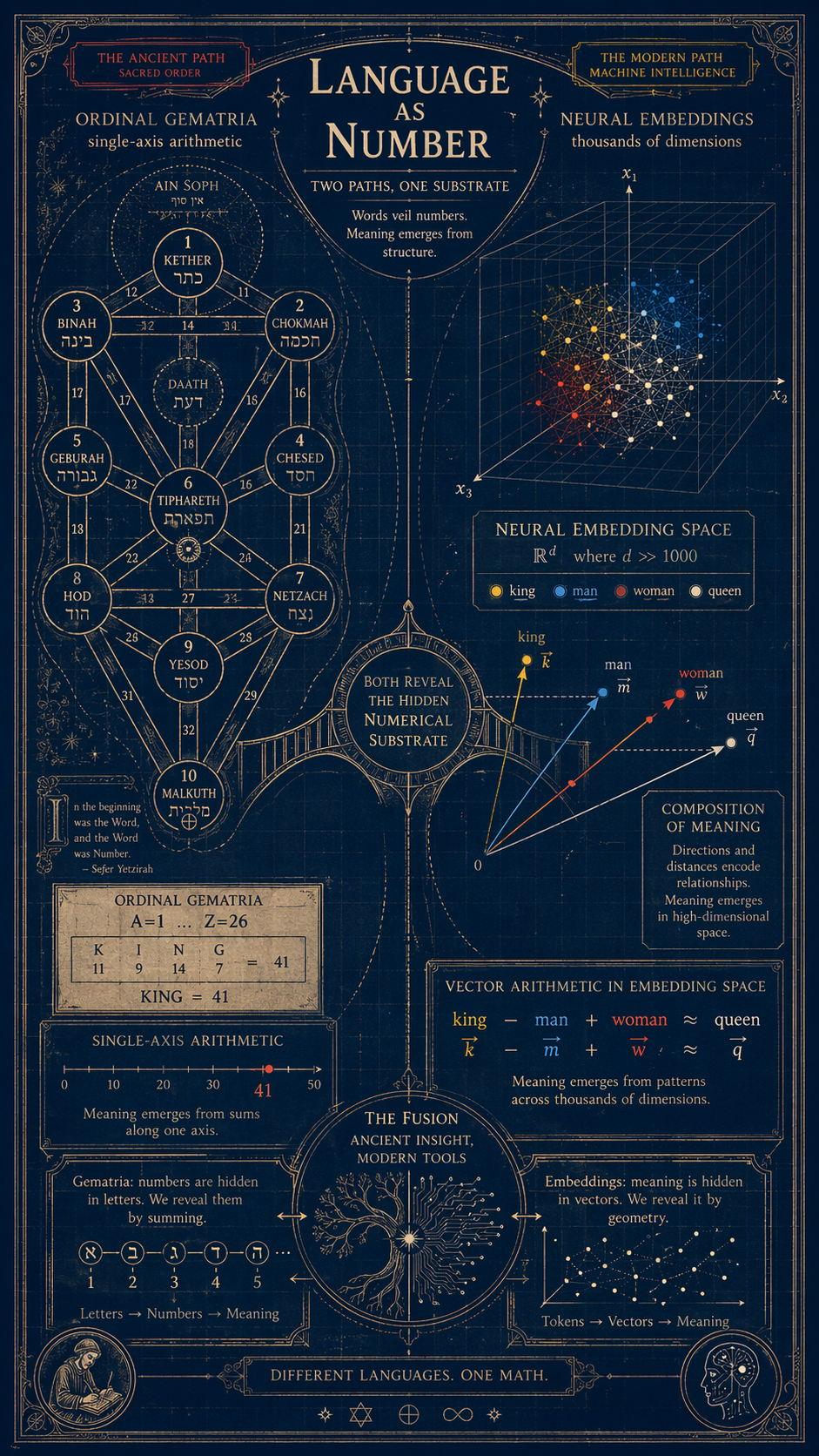
Now compare the two methods honestly:
| Paralells | Gematria | LLM Embeddings |
|---|---|---|
Letters are mapped to | 1 number | ~8,000 numbers |
Meaning lives in | the sum | the position |
Meaning is extracted by | arithmetic | arithmetic |
Words with the same value are | “mystically linked” | semantically linked |
Dimensionality | 1 | thousands |
Reputation | superstitious | worth $3 trillion |
The Kabbalists and the Pythagoreans were not wrong about the method. They were wrong about the dimensionality. One axis is not enough to encode meaning — if it were, every word summing to 32 would share a soul. Eight thousand axes, however, turn out to be almost exactly enough. This is not a coincidence; it is a measurement. Every time an AI lab increases the embedding dimension and the benchmarks creep up, we are learning how many axes of meaning language actually has.
The Pythagoreans were therefore approximately right in the same way that a medieval cartographer who draws the coast of Africa as a wavy line is approximately right. The shape is wrong. The claim that there is a shape is correct.
What Wittgenstein Almost Said
In a margin of the Philosophical Investigations — it does not actually exist there; I am about to make this up, and I want you to notice — one could imagine Wittgenstein writing:
“An arithmetic hidden from the speaker, but one the language itself has always known.”
The line fits him uncomfortably well. Most of his later work is the claim that meaning lives in use, and that the speaker never has full access to the rules of the game they are playing. Ordinal Gematria is the crudest possible version of that claim: the numbers are already there, baked into the alphabet, summable by a child, and yet no one consults them. Embedding vectors are the sophisticated version: the numbers are already there, baked into the statistical structure of a trillion-word corpus, extractable by a matrix multiplication, and yet no one consults them either — except the model.
Both are cases of a sub-symbolic reality hiding under a symbolic one. The speaker points at meaning and misses. The arithmetic points at meaning and hits. Language has known all along.
The Calculator, and Why It Is Here
Below this post, I have embedded a small interactive tool. I am calling it the Gematriaculator. Give it a number; it gives you back all the German and English words whose letters sum to that number, ranked by how often they actually appear in speech — so you will not be drowned in dictionary cruft like aardwolves or Zymurgie.
I do not claim the tool reveals mystical correspondences. I only claim it reveals coincidences, and that you will notice which of them feel significant. That is the Pythagorean experiment, conducted in your browser, with the training wheels on.
Try 32, if you like. Start with Damn. Go from there.
—Part 5.1, originally meant to be next, is deferred: the question of whether a human mind, trained on enough language and fed enough sweet music and strawberry π, can learn to see through a few hundred dark matter embedding dimensions without being Vera Rubin. We will get there.








