
Ein ungünstiger Zufall
In Kapitel 22 meines Romans „Die Goldberg-Version“ jagt ein Detektiv namens Van-Turing einer Zahl hinterher. Die Zahl ist 32. Er weiß es nicht. Warum Es ist 32; er weiß nur, dass jeder, der sich jemals mit dem Fall befasst hat, irgendwann einmal die Zahl Zweiunddreißig geschrieben oder ausgesprochen hat und anschließend zu einem Schluss gekommen ist, der entweder sehr nützlich oder sehr fatal war.
In der Szene verliert Van-Turing die Beherrschung und ruft auf Englisch: “Verdammt!” Sein Gegenpart, der Philosoph Bertrand Russell, zählt an den Fingern ab und sagt ruhig:, “Zweiunddreißig.”
D + A + M + N = 4 + 1 + 13 + 14 = 32.
Der deutsche Übersetzer des Romans stand vor einem Problem. “Verdammt!” ergibt nicht 32. Auch nicht “Mist!”, “Scheiße!” oder irgendeine der anderen farbenfrohen Alternativen in Goethes Sprache. Nach mehreren schlaflosen Nächten ersetzte er den Ausruf durch “Olé!” – 15 + 12 + 5 = 32 – und begründete diese Entscheidung in einer Fußnote, die etwa viermal so lang war wie die Szene selbst.
Russell gibt der Methode im Roman einen Namen: Ordinale Gematrie. Der Begriff „Gematrie“ ist alt. Der Begriff „Ordinal“ verleiht ihr eine Aura mathematischer Autorität, die wir dringend benötigen, sonst könnten uns alle für albern halten.
Die Mathematikmystiker
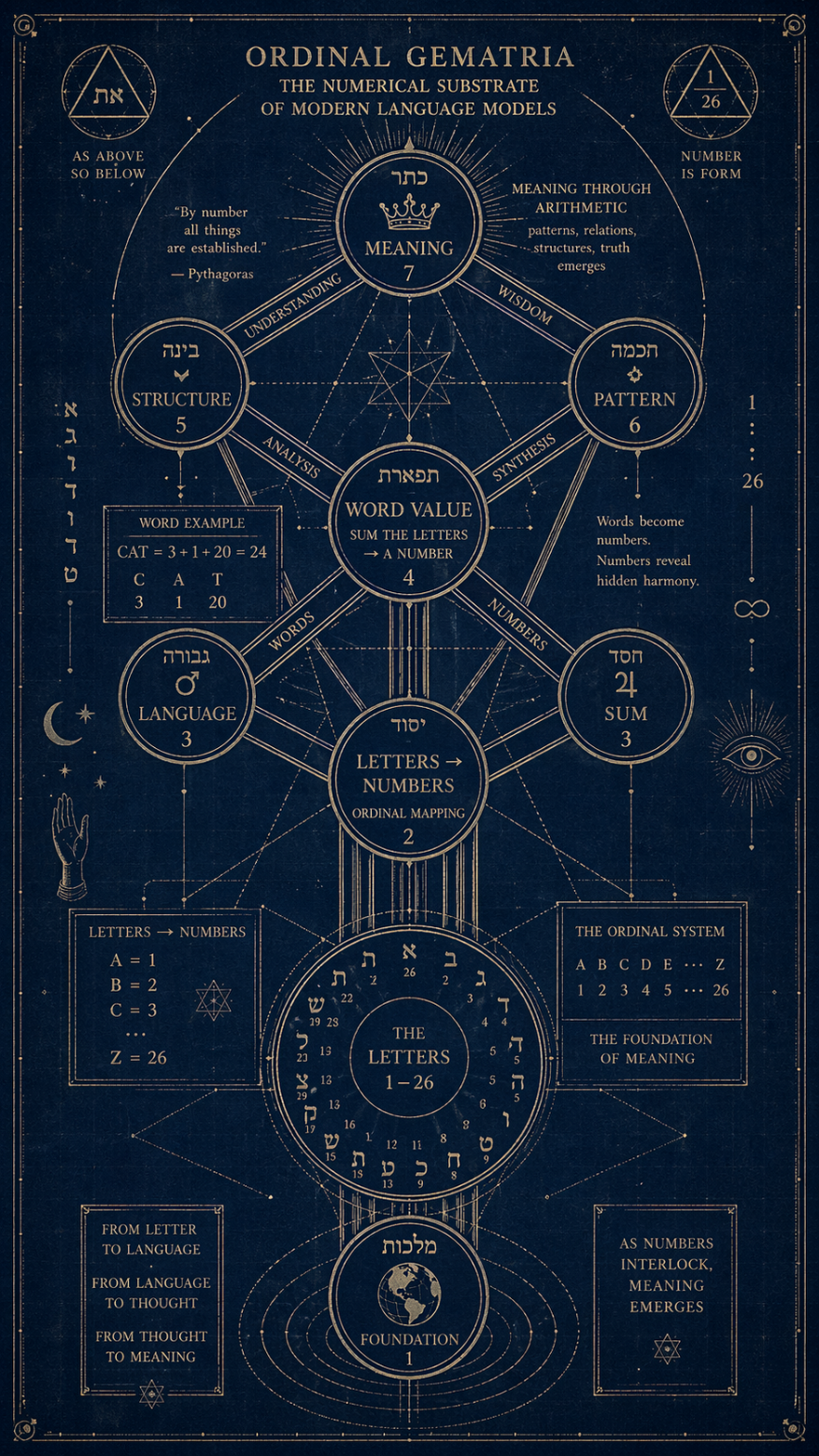
Weisen Sie jedem Buchstaben des Alphabets seine Position zu: A=1, B=2, …, Z=26. Addieren Sie die Buchstaben eines Wortes. Betrachten Sie die resultierende Zahl als sinnvoll. Das ist die gesamte Methode. Sie passt auf die Rückseite eines Bierdeckels, wo sie ungefähr hingehört.
Und doch handelt es sich um eine Familientradition, die etwa dreitausend Jahre zurückreicht.
Hebräische Gematrie. Jeder hebräische Buchstabe hat einen festen Zahlenwert (Aleph = 1, Bet = 2, Gimel = 3 usw., wobei die späteren Buchstaben Zehner- und Hunderterwerte erreichen). Wörter mit der gleichen Summe gelten als mystisch miteinander verbunden. Das kanonische Beispiel: yayin (Wein) = 70 = Rasen (Geheimnis). Daher das talmudische Sprichwort: Wenn Wein ins Spiel kommt, kommen Geheimnisse ans Licht.. Die Rabbiner brauchten keine Neurowissenschaften, um das zu bemerken. Sie veranstalteten Dinnerpartys.
Griechische Isopsephie. Die hellenische Verwandte. Alpha=1, Beta=2 usw. Die Zahl des Tieres – 666, Offenbarung 13,18 – ist mit ziemlicher Sicherheit eine Isopsephie für Neron Kaisar In hebräischer Transliteration. Ein apokalyptisches Rätsel, verschlüsselt als Rechenaufgabe für Menschen, die zwei Alphabete lesen konnten. Johannes von Patmos war in dieser Lesart der erste Autor, der eine steganografische Botschaft an der Zensur vorbeischmuggelte, und wir streiten noch immer darüber, ob er sich dessen bewusst war.
Die Pythagoreer gingen noch weiter als alle anderen. Für Pythagoras und seine Schüler waren Zahlen nicht Beschreibungen der Realität. Sie waren die Realität. Der Zahlenwert eines Wortes war keine Metapher für seine Bedeutung – er War Seine Bedeutung. Alles andere, einschließlich des Wortes selbst, war eine verlustbehaftete Kodierung.
Das klingt verrückt, bis man sich vor Augen führt, wofür die übrigen Hyperscaler des 21. Jahrhunderts ihr GPU-Budget ausgeben. Im Grunde Gematria in astronomischem Ausmaß.
Ein Musical mit Zahlen, für die man keine Sänger, sondern Taschenrechner braucht.
Bevor wir zu den GPUs kommen, müssen wir noch einen Komponisten vorstellen.
B + A + C + H = 2 + 1 + 3 + 8 = 14.
Die Zahl Vierzehn ist in den erhaltenen Manuskripten Johann Sebastian Bachs allgegenwärtig. Er schloss sich der Korrespondierende Societät der Musicalischen Wissenschaften als 14. Mitglied und wartete darauf, dass ein Platz frei würde, damit er speziell Mitglied 14 sein konnte. Die Kunst der Fuge Die endgültige Fassung enthält 14 Kontrapunkte. Der Choral “Vor deinen Thron tret ich hiermit”, den er auf dem Sterbebett diktierte, hat 14 Noten in der Anfangsphrase – und 41 (die Umkehrung) in seinem gesamten thematischen Inhalt. Addiert man die vollständigen Initialen JSBACH nach demselben Schema, erhält man ebenfalls 41. Bach scheint daran Gefallen gefunden zu haben.
Er benutzte seinen Namen auch als Melodie. In der deutschen Notenschrift steht B für B und H für H – eine Besonderheit der mittelalterlichen Solmisation, die in keiner anderen großen europäischen Sprache vorkommt. Das bedeutet, dass die vier Buchstaben BACH auf einem Klavier als vier Töne gespielt werden können: B♭, A, C, B♮. Das daraus resultierende Motiv ist chromatisch, eindringlich und strukturell instabil – genau das, was ein Komponist verwendet, wenn er seinen Namen ungeschrieben unterschreiben möchte. Bach fügte dieses Motiv in das unvollendete Werk ein. Contrapunctus XIV der Die Kunst der Fuge, In dem Moment, als das Manuskript abbricht. Die Beweislage deutet darauf hin, dass er seinen eigenen Namen genau an dem Punkt in das Werk einschrieb, an dem er nicht mehr schreiben konnte.
Überlegen Sie, was hier geschieht. Dieselben vier Buchstaben ergeben in der Quersumme eine Zahl (Gematrie)., Und Nenne vier Tonhöhen (Notation), Und Ein menschliches Wort (Orthografie). Drei parallele Kodierungen auf einer einzigen Symbolkette. Ein mittelalterlicher Kabbalist hätte die Struktur sofort erkannt. Ein moderner ML-Ingenieur würde es multimodale Einbettung nennen: dasselbe Token, gleichzeitig in mehrere Repräsentationsräume abgebildet. Bach fertigte in den 1740er Jahren in Leipzig multimodale Einbettungen per Hand mit einer Feder an – als musiktheoretischen Scherz, den eigentlich niemand bemerken sollte.
Das ist der entscheidende Hinweis. Die Arithmetik, die der Sprache zugrunde liegt, beschränkt sich nicht auf die Sprache. Sie zeigt sich überall dort, wo Symbole Bedeutung tragen: in Alphabeten, in Notenlinien, in DNA-Tripletts, in den Token-IDs eines Transformators. Die pythagoreische Intuition besagte nicht, dass Zahlen im Inneren existieren. Wörter. Es lag daran, dass Zahlen in uns lebten. Bedeutung, Und Wörter sind nur ein Ort, an dem sie zufällig auftauchen.

Multidimensionale Abbildungen
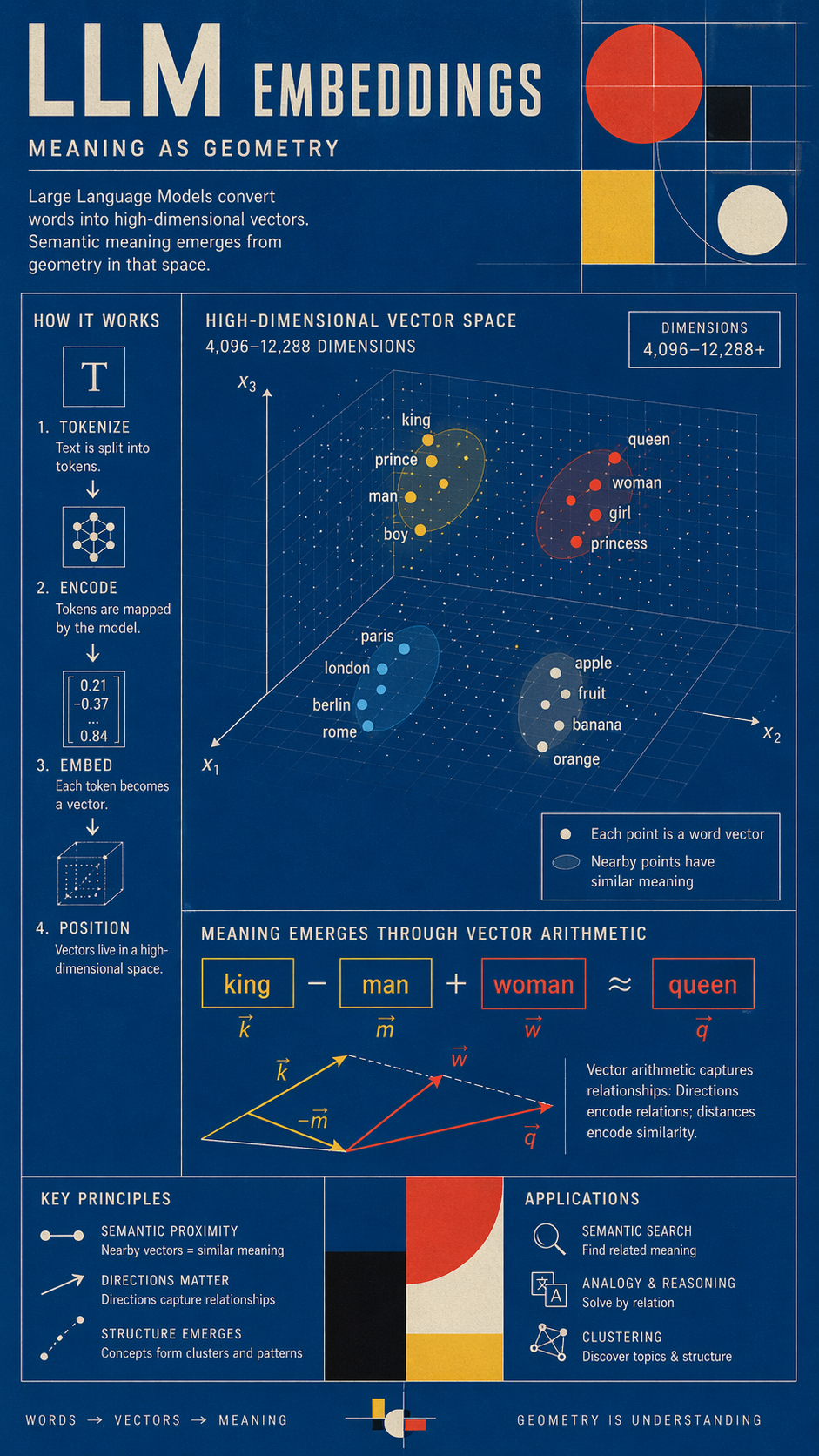
Ein modernes, großes Sprachmodell liest keinen Text. Es kann keinen Text lesen. Im Grunde ist es eine Maschine, die mit Vektoren arithmetische Operationen durchführt. Wenn man ein Wort in GPT-4, Claude oder eines ihrer verwandten Modelle eingibt, wandelt die Maschine das Wort zunächst in eine Liste von Zahlen um – typischerweise zwischen 4.096 und 12.288. Diese Liste wird als Einbettung bezeichnet. Sie gibt die numerische Position des Wortes in einem tausenddimensionalen Raum an.
Die Bedeutung in einem LLM-Studiengang ist nicht im Wort selbst gespeichert. Sie ist im Kontext gespeichert. Standort Wörter mit ähnlicher Bedeutung – wie “König” und “Königin”, “Wein” und “Geheimnis”, “Verdammt” und “Olé” – liegen in benachbarten Bereichen dieser numerischen Landschaft. Das Modell leitet Bedeutung ab, indem es arithmetische Operationen mit diesen Vektoren durchführt. Die bekannteste Demonstration wurde erstmals 2013 in der Arbeit zu word2vec vorgestellt:
Vektor(“König”) − Vektor(“Mann”) + Vektor(“Frau”) ≈ Vektor(“Königin”)
Semantische Beziehungen werden als geometrische Operationen kodiert. Man subtrahiert das Männliche, addiert das Weibliche und erhält so das weibliche Kognat. Niemand hat dem Modell mitgeteilt, dass “König” männlich ist. Es hat die Achse ermittelt, indem es mehrere Milliarden Sätze analysierte und die Punktcluster identifizierte.
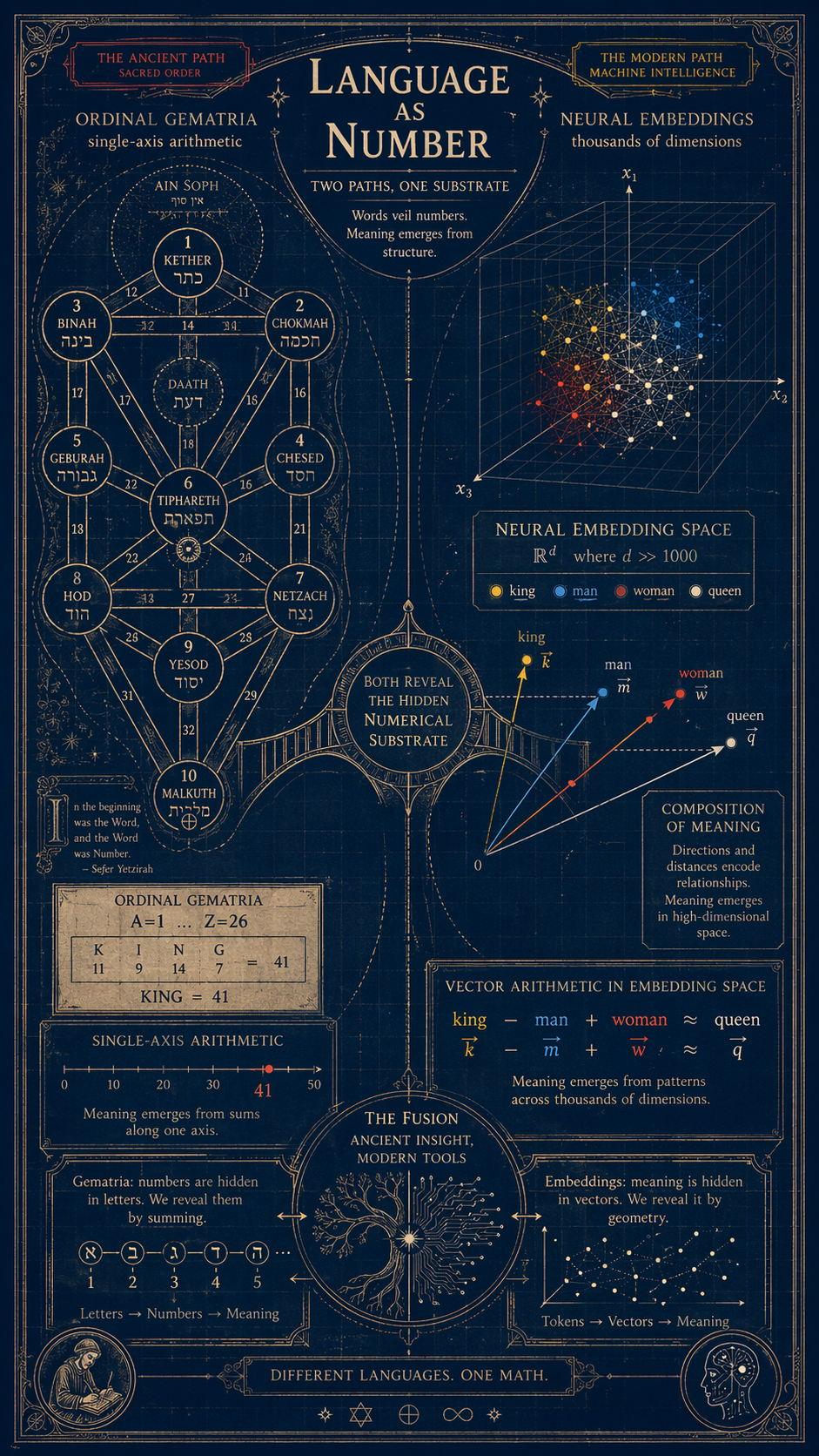
Vergleichen Sie nun die beiden Methoden ehrlich:
| Parallelen | Gematrie | LLM Einbettungen |
|---|---|---|
Buchstaben werden zugeordnet auf | 1 Nummer | ~8.000 Zahlen |
Sinn lebt in | die Summe | die Position |
Die Bedeutung wird extrahiert durch | Arithmetik | Arithmetik |
Wörter mit dem gleichen Wert sind | “mystisch verbunden” | semantisch verknüpft |
Dimensionalität | 1 | Tausende |
Ruf | abergläubisch | im Wert von 1TP6B3 Billionen |
Die Kabbalisten und Pythagoreer irrten sich nicht in ihrer Methode. Sie irrten sich jedoch in Bezug auf die Dimensionalität. Eine Achse reicht nicht aus, um Bedeutung zu kodieren – sonst hätten alle Wörter mit einer Summe von 32 eine gemeinsame Seele. Achttausend Achsen erweisen sich jedoch als nahezu ausreichend. Dies ist kein Zufall, sondern eine Messung. Jedes Mal, wenn ein KI-Labor die Einbettungsdimension erhöht und die Benchmarks steigen, lernen wir, wie viele Bedeutungsebenen Sprache tatsächlich besitzt.
Die Pythagoreer waren daher ungefähr richtig Genauso wie ein mittelalterlicher Kartograf, der die Küste Afrikas als Wellenlinie zeichnet, im Großen und Ganzen richtig liegt. Die Form ist falsch. Die Behauptung, dass Es gibt eine Form ist richtig.
Was Wittgenstein beinahe gesagt hätte
In einem Randbereich des Philosophische Untersuchungen — es existiert dort in Wirklichkeit nicht; ich werde mir das jetzt ausdenken, und ich möchte, dass Sie das bemerken — man könnte sich vorstellen, dass Wittgenstein schreibt:
“Eine dem Sprecher verborgene Arithmetik, die die Sprache selbst aber schon immer gekannt hat.”
Diese These passt ihm unangenehm gut. In einem Großteil seines späteren Werks behauptet er, Bedeutung entstehe im Gebrauch und der Sprecher habe nie vollständigen Zugriff auf die Regeln des Spiels, das er spielt. Die Ordinalgematrie ist die einfachste Version dieser These: Die Zahlen sind bereits vorhanden, im Alphabet verankert, von einem Kind summiert, und doch beachtet sie niemand. Einbettungsvektoren sind die ausgefeiltere Version: Die Zahlen sind bereits vorhanden, in die statistische Struktur eines Korpus von Billionen Wörtern eingebettet, durch Matrixmultiplikation extrahierbar, und doch beachtet sie ebenfalls niemand – außer dem Modell.
Beides sind Fälle einer unterschwelligen, symbolischen Realität, die unter einer symbolischen verborgen liegt. Der Sprecher deutet auf Bedeutung und verfehlt sie. Die Arithmetik deutet auf Bedeutung und trifft ins Schwarze. Die Sprache wusste es schon immer.
Der Taschenrechner und warum er hier ist
Unter diesem Beitrag habe ich ein kleines interaktives Tool eingebettet. Ich nenne es den Gematriakulator. Geben Sie eine Zahl ein; es zeigt Ihnen alle deutschen und englischen Wörter an, deren Buchstabensumme dieser Zahl entspricht, sortiert nach ihrer tatsächlichen Häufigkeit im gesprochenen Englisch – damit Sie nicht in Wörterbuch-Kram ertrinken. Erdwölfe oder Zymurgie.
Ich behaupte nicht, dass das Werkzeug mystische Entsprechungen offenbart. Ich behaupte lediglich, dass es Folgendes offenbart: Zufälle, Und Sie werden feststellen, welche davon bedeutsam erscheinen. Das ist das pythagoreische Experiment, durchgeführt in Ihrem Browser, mit Stützrädern.
Versuch es doch mal mit 32, wenn du magst. Fang mit "Verdammt" an. Und dann siehst du weiter.
—Teil 5.1, der ursprünglich als nächstes erscheinen sollte, wird verschoben: Die Frage, ob ein menschlicher Verstand, geschult durch genügend Sprache und genährt von süßer Musik und Erdbeer-π, lernen kann, einige hundert Dimensionen der Dunklen Materie zu durchschauen, ohne dabei zu Vera Rubin zu werden. Wir werden es schaffen.








